iOS Function Patching
20 Jan 2013, 08:03 PSTOn Mac OS X, mach_override is used to implement runtime patching of functions. It essentially works by marking the executable page as writable, and actually inserting a new function prologue into the target function.
On iOS, pages are W^X: a page can be writable, or executable, but it's never allowed to be both. This has required finding inventive solutions, such as trampoline pools to support things such as imp_implementationWithBlock() and libffi's closures.
However, the trampoline approach will not work for patching arbitrary OS code; you somehow need to be able to modify the code in place, but there's no way to actually write to a code page.
Last night, Mike Ash and I were jokingly discussing how we could implement this (badly) using memory protections and signal handlers.
Enter libevil:
void (*orig_NSLog)(NSString *fmt, ...) = NULL;
void my_NSLog (NSString *fmt, ...) {
orig_NSLog(@"I'm in your computers, patching your strings ...");
NSString *newFmt = [NSString stringWithFormat: @"[PATCHED]: %@", fmt];
va_list ap;
va_start(ap, fmt);
NSLogv(newFmt, ap);
va_end(ap);
}
evil_init();
evil_override_ptr(NSLog, my_NSLog, (void **) &orig_NSLog);
NSLog(@"Print a string");
You should not use this code. Seriously.
How it Works
libevil uses VM memory protection and remapping tricks to allow for patching arbitrary functions on iOS/ARM. This is similar in function to mach_override, except that libevil has to work without the ability to write to executable pages.
This is achieved as follows:
- All mapped segments of the executable to be patched are remapped to a new address for preservation.
- The target page containing the function to be patched is set to PROT_NONE, triggering a crash if one attempts to execute anything in that page.
- A custom signal handler interprets the crash:
- If the IP of the crashed thread points at a patched function, thread state is rewritten to point at the new user-supplied function.
- If the IP of the crash thread points at some other address in the patched page, it is rewritten to execute from the mirrored copy of the binary.
- If the si_addr of the crash is within the patched page, all registers containing that address are rewritten to point at the mirrored copy of the binary.
The entire binary is remapped as to 'correctly' handle PC-relative addressing that would otherwise fail. There are still innumerable ways that this code can explode in your face. Remember how I said not to use it?
A fancier implementation would involve performing instruction interpretation from the crashed page, rather than letting the CPU execute from remapped pages. This would involve actually implementing an ARM emulator, which seems like drastic overkill for a massive hack.
The Code
The implementation only supports ARM, so you can only test it out on your iOS device. I've posted the code and a sample application on github.
Reliable Crash Reporting - v1.1
19 Jan 2013, 12:37 PSTA bit over a year ago, I wrote a blog post on Reliable Crash Reporting, documenting the complexity of reliably generating crash reports and how seemingly innocuous decisions could lead to failure in the crash reporter, or even corruption of user data. This was based on my experience in writing and maintaining PLCrashReporter, a standalone open-source crash reporting library that I've been maintaining (and using in our production applications) since around 2008.
Given that there have been a number of new entrants into the space, including KSCrash and Crashlytics 2.0, I thought it would be fun to revisit the previous post and review the current state of the art.
While I'd suggest reading the original post for the backstory on what makes reliable crash reporting difficult -- and why it matters -- I'll repeat the most pertitent section here:
Implementing a reliable and safe crash reporter on iOS presents a unique challenge: an application may not fork() additional processes, and all handling of the crash must occur in the crashed process. If this sounds like a difficult proposition to you, you're right. Consider the state of a crashed process: the crashed thread abruptly stopped executing, memory might have been corrupted, data structures may be partially updated, and locks may be held by a paused thread. It's within this hostile environment that the crash reporter must reliably produce an accurate crash report.
Today I'll touch on two reliability issues that remain in modern crash reporters -- handling stack overflows, and async-safety. The stack overflow issue is especially frustrating to me, given that it affects PLCrashReporter, too.
Async-Safety
Imagine that the application has just acquired a lock prior to crashing. If the crash reporter attempts to acquire the same lock, it will wait forever: the crashed thread is no longer running, and it will never release the lock. When a deadlock like this occurs on iOS, the application will appear unresponsive for 20+ seconds until the system watchdog terminates the process, or the user force quits the application, and no valid crash report will be written.
In my previous post, I touched on async-safety issues around Objective-C and re-entrantly running the user's code. Most crash reporters have moved away from those APIs, but have introduced new async-safety issues in the process.
One of the common issues I found in all new reporters was reliance on the pthread(3) API to fetch thread information, including thread names. These APIs are not async-safe, however, and will acquire a global lock in most cases -- including when fetching a thread's name via pthread_getname_np(3). The result is that if your code crashes while any thread is holding the pthread thread-list lock, the entire crash reporter will deadlock. Since the crash reporters suspend all threads during reporting, this can occur even if the pthread calls themselves do not crash, but rather, a thread just happened to be executing a pthread() call at the time a crash occured.
I put together the following test case to demonstrate this issue. It will cause crash reporters that make use of pthreads to deadlock: either until the user force-quits, or the iOS watchdog kills the process (after 20 or so seconds.)
#import <pthread.h>
static void unsafe_signal_handler (int signo) {
/* Try to fetch thread names with the pthread API */
char name[512];
NSLog(@"Trying to use the pthread API from a signal handler. Is a deadlock coming?");
pthread_getname_np(pthread_self(), name, sizeof(name));
// We'll never reach this point. The process will stop here until the OS watchdog
// kills it in 20+ seconds, or the user force quits it. No crash report (or a partial corrupt
// one) will be written.
NSLog(@"We'll never reach this point.");
exit(1);
}
static void *enable_threading (void *ctx) {
return NULL;
}
int main(int argc, char *argv[]) {
/* Remove this line to test your own crash reporter */
signal(SIGSEGV, unsafe_signal_handler);
/* We have to use pthread_create() to enable locking in malloc/pthreads/etc -- this
* would happen by default in any real application, as the standard frameworks
* (such as dispatch) will trigger similar calls into the pthread APIs. */
pthread_t thr;
pthread_create(&thr, NULL, enable_threading, NULL);
/* This is the actual code that triggers a reproducible deadlock; include this
* in your own app to test a different crash reporter's behavior.
*
* While this is a simple test case to reliably trigger a deadlock, it's not necessary
* to crash inside of a pthread call to trigger this bug. Any thread sitting inside of
* pthread() at the time a crash occurs would trigger the same deadlock. */
pthread_getname_np(pthread_self(), (char *)0x1, 1);
return 0;
}
This is the primary reason PLCrashReporter does not provide thread names in its crash reports; this requires either calling non-async-safe API, or directly accessing system-private structures that are often changed release-to-release. If there's significant user demand, I may consider adding optional support for fetching thread names by poking around in system-private structures.
Stack Overflow
When a thread's stack overflows, there is is no stack space left over for a signal handler to use, which results in the inability to record the crash.
This can be handled partially with sigaltstack(2), which instructs the kernel to insert an alternative stack for use by the signal handler. This is functional but imperfect, as the API requires registering a custom signal stack for every thread in the process. Despite the sigaltstack(2) man page's implication that the registered stack is process-global, the stack is only enabled for the thread calling sigaltstack(2). The result is that stack overflows can only be handled on the main thread, unless additional threads are manually registered.
On Mac OS X, we can make use of a more capable API -- Mach exception handling -- to fully solve this problem. Since Mach exceptions are handled on a dedicated thread (or out of process entirely), the crashed thread's stack is entirely independent of the crash reporter. Unfortunately, the requisite Mach definitions are private on iOS, and have been since I originally wrote PLCrashReporter. This issue previously arose when Unity had their user's apps rejected in 2009, due to Mono's direct use of the Mach exc_server() API, and they were forced to release an update that avoided the use of the API in question.
Given that the structures and definitions required for a full implementation of Mach exception handling are private (at least, insofar as I've been able to determine), PLCrashReporter has long relied on sigaltstack(2) to provide the ability to report crashes on the main thread.
Unfortunately, sigaltstack(3) is broken in later iOS releases. In fact, it simply doesn't do anything at all. I've filed rdar://13002712 (SA_ONSTACK/sigaltstack() ignored on iOS) to report the issue to Apple, but in the meantime, I can see no way to detect stack overflow on iOS using only public API.
I've implemented Mach exception handling in PLCrashReporter for Mac OS X, and it could be used as a work-around on iOS, but I'm uncomfortable with providing something that relies on undocumented and/or private SPI. To make sure I wasn't missing something obvious, I even reviewed the KSCrash and Crashlytics 2.0 implementations to determine how they work around this issue, since both use Mach exceptions. Unfortunately, KSCrash appears to have copied in the private structure definitions from the kernel source, and from what I can tell from disassembling their code, Crashlytics copied the (private on iOS) Mach headers from the Mac or Simulator SDKs.
To confirm, I contacted Apple DTS. Their reply was as follows:
Our engineers have reviewed your request and have determined that this would be best handled as a bug report, which you have already filed. There is no documented way of accomplishing this, nor is there a workaround possible.
This is a frustrating position to be in; it seems the only choices are either to leave stack overflow reporting broken, or make use of seemingly private API. I've filed a radar requesting that the requisite Mach defs/headers be made public. In the mean time, I'm considering providing iOS Mach exception support as a user-configurable feature. At the very least, it could be enabled only for development builds.
Conclusion
Crash reporting is a complex enough topic that you can be reasonably assured that 1) You will always get something wrong, and 2) there is always room to improve. There are always trade-offs and edge-cases in engineering, and especially so in crash reporting, in which one operates in an environment with significant reliability restrictions, coupled with the ability to fetch, update, and permute memory and thread state at will.
When it comes to implementing something complex like crash reporting correctly, projects like Google's Breakpad deserve considerable admiration. They've invested years of very smart people's time towards getting crash reporting right, and have been deployed on a huge number of desktops via Chrome and Firefox. I'm working to incorporate some of the solid design decisions that have gone into Breakpad -- such as placing guard pages around (or locking outright) memory that is required for function after a crash.
Going forward, I'll probably be writing more informal (and shorter) posts to explore particular aspects of crash reporting. If you have any questions, or have anything you think would be worth covering here, feel free to drop me a line.
FatELF Toolchain Drivers
16 Dec 2012, 10:45 PSTIntroduction
One of the handy features in Mac OS X's universal binary support is the ability to easily compile a binary for multiple architectures with one command. This simplifies the process of producing a binary for multiple devices, avoiding the need to run the build multiple times and manually stitch together the results.
For example, one could build a mixed armv7, armv7s, and armv6 binary -- with thumb enabled only for armv6 -- with the following command:
gcc -arch armv7 -arch armv7s -arch armv6 -Xarch_armv6 -mthumb
In reality, the compiler is still being run multiple times; an arch-aware driver handles automatically running the compilers, writing the build results to temporary files, and then stitching them together with lipo(1). In the case of clang, the code to do this actually lives in clang itself. However, in the case of gcc, Apple implemented a front-end driver that sits in front of the actual gcc executables, called driverdriver.c. A similar driver is also supplied for as(1); it handles calling out to the correct assembler, but only supports a single -arch flag.
Haiku Implementation
In implementing FatELF on Haiku, I needed the functionality provided by these drivers. Unfortunately, they were written somewhat non-portably for Mac OS X, and in the case of the gcc driverdriver.c, relied on internal GCC APIs that have been removed in later versions of GCC.
To solve this, I went ahead and wrote new front-end drivers that work with modern gcc(1) and as(1) versions. I implemented them as part of the Haiku fatelf-tools project, but they're meant to be portable to multiple hosts, and should be straight-forward to hoist out for other purposes. These could be used, for example, to support building universal binaries using more recent gcc releases on Mac OS X, where the traditional driverdriver.c cannot otherwise be used (due to reliance on GCC APIs that have now been removed).
If you want to review the initial implementation, the drivers can be found in my haiku-buildtools repository: fatelf-gcc.c, fatelf-as.c.
With these tools, I can build multi-arch Haiku FatELF binaries using the standard GCC toolchain:
landonf@lambda:fatelf> ./fatelf-gcc -arch i386 -arch x86_64 -c foo.c -o foo.o landonf@lambda:fatelf> ./fatelf-info foo.o foo.o: FatELF format version 1 2 records. Binary at index #0: OSABI 0 (sysv: UNIX System V) version 0, 32 bits Littleendian byteorder Machine 3 (i386: Intel 80386) Offset 4096 Size 547 Target name: 'i386:32bits:le:sysv:osabiver0' or 'record0' Binary at index #1: OSABI 0 (sysv: UNIX System V) version 0, 64 bits Littleendian byteorder Machine 62 (x86_64: AMD x86-64) Offset 8192 Size 799 Target name: 'x86_64:64bits:le:sysv:osabiver0' or 'record1'
FatELF ('Universal') Binaries for Haiku
26 Nov 2012, 16:05 PSTIntroduction
One of the features that I think has been critical to Apple's ability to leverage improvements in underlying CPUs -- as well as weather migrations to completely new architectures -- has been their Universal Binary Format.
The concept is fairly simple, and dates back to NeXT, where they targeted a plethora of available platforms. Put succinctly, a universal binary is composed of:
- A set of records describing the supported architectures.
- The range of the file at which an architecture executable can be found.
- The actual architecture-specific executables, concatenated at the end of the fat headers.
For such a seemingly simple idea, the value is huge: universal binaries simplify the user experience for application users and developers alike.
From the user's perspective, they aren't forced to choose between x86-32 and x86-64 binaries depending on what version of the OS they happened to install. 32-bit and 64-bit Macs can use the same installation media, and web sites containing application downloads don't need to list two (or more) different downloads for each version. When new iPhones are released with updated ARM revisions, older binaries that are forwards-compatible can keep running, and newer binaries can be selected when supported by the hardware, maximizing the user (and developer's) ability to seamlessly take advantage of improvements in hardware revisions.
At runtime, the OS can avoid loading a duplicate set of libraries for binaries that are forwards-compatible -- for instance, ARMv6+hardfloat binaries can be linked against ARMv7 libraries on the iPhone -- and are. When hosting plugins, the hosting application can automatically 'downgrade' to the lowest common denominator ABI by relaunching itself, thus allowing for gradual transitions between old ABIs and new ABIs -- this was done by Apple in System Preferences when the entire OS switched over to x86-64, allowing System Preferences to switch back to i386 inthe case where the user still had legacy plugins installed.
From a developer's perspective, the universal binary ecosystem makes it trivial to support building their application for multiple architectures. While testing still needs to be done on the native system, a binary can be built and linked for all supported architectures simply by supplying the appropriate -arch flags to the compiler, using the same set of libraries and headers. Supporting a new target from your existing desktop system is as easy as downloading an updated SDK and including the target architecture in your build. Binaries that are required for the build (such as a protobuf compiler) can be compiled universal and included in the build system for any supported build host.
Even on the App Store, where Apple controls distribution and in theory could automatically supply different versions of an application for different devices, Apple has continued to leverage universal binaries, to Apple's advantage. The simplicity of being able to synchronize a single binary with multiple phones remains, but in addition, Apple has been able to rapidly deploy new ARM hardware features and see immediate developer adoption, because the cost and implementation costs are so low. By comparison, Linux, which traditionally has not supported fat binaries, has had to weigh the advantages of adopting new hardware features with the cost of having to build and deploy a completely new graph of the OS and all available software for that OS.
FatELF - Universal Binaries For the Rest of Us
Apple is largely unique in their use of the Mach-O binary format and fat binaries, but there has been an effort to bring fat binaries to Linux, and other operating systems that use the (much more popular) ELF binary format. Ryan Gordon -- who has been a driving force in porting numerous games to Mac OS X and Linux (including Quake III Arena) -- set out in 2009 to define the FatELF format, which provides support for fat binaries on ELF-using platforms. Ryan implemented a full suite of command line tools for assembling fat binaries, Linux kernel support, and the necessary patches for binutils, gdb, glibc, etc.
Using Ryan's specifications and tools, I went ahead and implemented initial FatELF support for the Haiku kernel, boot loader, and runtime loader. With this work -- assuming the patches are integrated upstream -- Haiku will be able to use universal binaries for the kernel, kernel modules, shared libraries and executables.
The next step will be to extend these additions to the developer tools, with the goal of making it seamless to produce FatELF binaries using the same approach that Apple has used for Mac OS X and iOS. Once completed, I can begin to integrate the new toolchain into the build system, and start on the goal of building a fully universal 32-bit/64-bit Haiku installation.
If you're curious, you can find my FatELF-enabled branch here.
Haiku VMware Drivers
17 Nov 2012, 17:07 PSTWho could not like BeOS?
Haiku Alpha 4 was recently released, to the excitement of everyone. Or, at least those of us that maintain a strong sense of nostalgia for pervasive multithreading and yellow window tabs.
If you feel the urge to satiate your nostalgia by hacking on Haiku under VMware, you'll find that the current alpha does not fully support the VMware SVGA display, or mouse integration. One solution would be to use VirtualBox, which has first-class Haiku support mainlined into their repository. Unfortunately, at least from my experience, VirtualBox does not have first-class Mac OS X support, and tends to crash my machine.
Fortunately, however, there are actually VMware mouse and display drivers in the Haiku repository; you can either build and install these into your existing installation, or you can build a custom installation image including the drivers -- it only takes a few minutes to build the full OS.
To build a custom image, follow the directions provided in the Building Haiku documentation to configure your checkout and build the standard cross toolchain. Once that's done, you'll need to create a build/jam/UserBuildConfig file and add the following lines:
AddDriversToHaikuImage graphics : vmware ; AddFilesToHaikuImage system add-ons input_server filters : vmware_mouse ; AddFilesToHaikuImage system add-ons accelerants : vmware.accelerant ;
If you build a normal image as documented in Compiling Haiku for x86, the in-kernel and userspace VMware drivers will be included. Note, however, that without full guest additions, enhanced guest features will not be available: window resizing will not automatically adjust the guest resolution, copy+paste will not be functional, shared folders are not supported, etc.
Silicon Labs CP210x UART to USB Driver
17 Nov 2012, 17:06 PSTIntroduction
Some months ago, I picked up a an Aeon Labs Z-Stick Series 2. The Z-Stick is USB-equipped Z-Wave controller, using CP210x chipset to provide access to the Z-Wave module's UART over USB. The official driver from Silicon Labs simply didn't work at all, timing out on any read or write to the device. So I decided to take a crack at writing my own driver.
The driver works great for my purposes -- I can turn my lights on and off without ever leaving my desk. Awesome, right?
The bad news? That's where I'm going to stop, at least for now. Between poor documentation, ambiguously defined behavior, and more layers of indirection than I can reasonably decipher in a spare afternoon, I've had my fill of IOKit for a while. Of the 1.2k lines of code in the driver so far, maybe 40 LoC actually has anything to do with talking to the CP210x; the rest is all IOKit-required boilerplate.
Adventures in IOKit
In my experience, third-party USB serial drivers for Mac OS X tend to be extremely buggy. Most of the drivers I've tested panic during use, don't work at all, or fail under relatively standard usage such as unplugging the device while running. I previously assumed that the entire blame for this rested on the driver's authors. Then I tried to write a USB serial driver for Mac OS X, and gained a whole new appreciation for anyone embarking on this journey.
If I were to revisit this in the future, I'd like to spend some time abstracting out the driver into a generic re-usable USB serial layer that I could use to implement additional drivers. Most USB serial devices have nearly identical interfaces -- a bulk input pipe, a bulk output pipe, and actual control requests that vary between devices, but tend to provide similar functionality -- a good fit for centralizing all the complex IOKit state management and boilerplate in one place. This is what Haiku does, to pretty good effect: compare the roughly 138 lines of Haiku's implementation with my IOKit monster
Getting the Source
If you'd like to use the driver -- or help with the remaining issues -- you can find the source available at the mac-cp210x project page. The additional work will be solving lifecycle issues around asynchronous device control messages and unplug/driver unload behavior, enabling the existing code to allow manual control over RTS/DTR lines, and implementing state updates on changes to the incoming control lines.
Otherwise, I'll probably revisit the code whenever spending a few weekends with IOKit sounds like fun again.
Reliable Crash Reporting
14 Sep 2011, 16:09 PDTIntroduction
PLCrashReporter is a standalone open-source library for generating crash reports on iOS. When I first wrote the library in 2008, it was the only option for automatically generating and gathering crash reports from an iOS application. Apple's iOS crash reports were not available to developers, and existing crash reporters — such as Google's excellent Breakpad — were not supported on iOS (Breakpad still isn't). Since that time, quite a few crash reporters and crash reporting services have appeared: Apple now provides access to App Store crash reports, a number of 3rd-party products and services were built on PLCrashReporter (such as HockeyApp, JIRA Mobile Connect), and some services have chosen to write their own crash reporting library (TestFlight, Airbrake, and others).
Despite this obvious interest in adopting crash reporting from iOS developers, there has remained little understanding of the complexities and difficulties in implementing a reliable and safe crash reporter, and many of the custom crash reporting libraries have been implemented improperly. It's my intention to explore what makes crash reporting difficult (especially on iOS), and provide real-world examples of how an impoperly written crash reporter can fail — sometimes with little fanfare, and sometimes with surprising consequences.
A Hostile Environment
Implementing a reliable and safe crash reporter on iOS presents a unique challenge: an application may not fork() additional processes, and all handling of the crash must occur in the crashed process. If this sounds like a difficult proposition to you, you're right. Consider the state of a crashed process: the crashed thread abruptly stopped executing, memory might have been corrupted, data structures may be partially updated, and locks may be held by a paused thread. It's within this hostile environment that the crash reporter must reliably produce an accurate crash report.
To reliably execute within this hostile environment, code must be "async-safe": it must not rely on external, potentially inconsistent state. More concretely, this means that a crash reporter must avoid APIs that have not been written explicitly to be executed with a signal handler, in a potentially crashed process. This excludes everything from malloc — the heap may have been corrupted, or partially updated — to Objective-C — locks may be held in the runtime, or data structures might be partially initialized. In fact, there's so little that you can do safely within a signal handler, it's much easier to define what you *can* do safely — a minimum number of system calls and APIs are defined to be async-safe, and those are the only APIs you can reliably call.
Thus, to be reliable and safe, a crash reporter must be written with async-safety in mind, eliminating or minimizing the risk inherent in operating within a hostile and corrupt environment. At this point, you might ask what I mean by "reliable and safe" — after all, if the process has already crashed, what's the worst that could happen? It crashes again? In fact, there's quite a bit that can go wrong, largely depending on the non-async-safe APIs that an unreliable crash reporter might rely on.
First, do no harm
The mission of a crash reporter is simple: report crashes, and provide enough information to debug them. As it turns out, if you know how to read the report, just about everything you need to debug nearly all crashes can be found in the backtraces, register state, and a bit of intuition about your own code (look for a future blog post on this subject).
However, a crash reporter should never make things worse — I'll cover three major ways it can do that:
- Relying on non-async-safe APIs: This can deadlock the process and cause a hang, resulting in a failure to report the crash. In the pathological case, this can result in corruption of users' data.
- Using overly simple APIs like backtrace(3): Blinds the developer to specific problems --- such as a stack overflow -- by being unable to report them.
- Discarding crashed thread's register state: Providing incomplete crash reports makes it practically impossible to debug certain classes of crashes.
Let's explore these failure cases with some real world examples.
Failure Case: Async-Safety and Deadlocking Objective-C
One of the more likely failure modes when dealing with a non-async-safe APIs is a deadlock. Imagine that the application has just acquired a lock prior to crashing. If the crash reporter's implementation then attempts to acquire the same lock, it will wait forever: the crashed thread is no longer running and will never release the lock. When a deadlock like this occurs on iOS, the application will appear unresponsive for 10-20 seconds until the system watchdog terminates the process, or the user force quits the application.
It is possible to trigger such a deadlock simply by using Objective-C within the signal handler. The Objective-C runtime itself maintains a number of internal locks, and if a thread happens to hold a runtime lock when a crash occurs, any use of Objective-C in the crash reporter itself will trigger a deadlock. This is dependent on timing, however — for the purposes of a providing a simple test case, I've created a contrived example that will reliably demonstrate the deadlock on ARM and x86:
static void unsafe_signal_handler (int signo) {
/* Attempt to use ObjC to fetch a backtrace. Will trigger deadlock. */
[NSThread callStackSymbols];
exit(1);
}
int main(int argc, char *argv[]) {
/* Remove this line to test your own crash reporter */
signal(SIGSEGV, unsafe_signal_handler);
/* Some random data */
void *cache[] = {
NULL, NULL, NULL
};
void *displayStrings[6] = {
"This little piggy went to the market",
"This little piggy stayed at home",
cache,
"This little piggy had roast beef.",
"This little piggy had none.",
"And this little piggy went 'Wee! Wee! Wee!' all the way home",
};
/* A corrupted/under-retained/re-used piece of memory */
struct {
void *isa;
} corruptObj;
corruptObj.isa = displayStrings;
/* Message an invalid/corrupt object. This will deadlock crash reporters
* using Objective-C. */
[(id)&corruptObj class];
return 0;
}
If you run this code on iOS or the simulator, you'll reliably trigger a deadlock in any crash reporter using Objective-C in its signal handler. While this specific example is somewhat contrived for the sake of serving as reliable test case, any use of Objective-C or any other non-async-safe function in a signal handler has the potential to trigger such a deadlock, and should be avoided.
Failure Case: Async-Safety and Data Corruption
The risk of data corruption is a far more potent concern than a deadlock. There are a surprising number of ways that this can occur — but what might be the most likely (and dangerous) mechanism to trigger data corruption is the reentrant running of the application's event loop.
Some crash reporters attempt to submit the crash report over the network immediately upon program termination. This introduces an interesting failure mode: spinning the runloop to handle network traffic may also trigger execution of the application's own code, and the application is then free to attempt to write potentially corrupt user data.
Consider a Core Data-based application, in which a model object is updated, and then saved:
person.name = name; person.age = age; // a crash occurs here person.birthday = birthday; [context save: NULL];
At the time of the crash, the managed object context contains a partially updated record — certainly not something you want saved to the database. However, if the crash reporter then proceeds to reentrantly run the application's runloop, any network connections, timers, or other pending runloop dispatches in your application will also be run. If the application code dispatched from the runloop contains a call to -[NSManagedObjectContext save:], you'll write a partially updated record to the database, corrupting the user's data.
This approach of executing non-reentrant, non-async-safe code from a crash reporter is particularly dangerous. To avoid this, the signal handler can not make use of higher-level networking APIs at crash time, and crash report implementations must not attempt to submit a crash report until the application has started again.
If added to your UIApplicationDelegate, the following code will print a message to the console if your crash reporter spins the runloop after a crash has occurred:
dispatch_async(dispatch_get_main_queue(), ^{
NSLog(@"APPLICATION CODE IS RUNNING - Crash reporter is spinning runloop");
});
*((int *)NULL) = 5; // trigger a crash
Failure Case: Stack Traces and Stack Overflow
There are two ways to implement backtrace support in a crash reporter (but only one of them is reliable):
- Use high-level APIs such as backtrace(3) or -[NSThread callStackSymbols] to fetch a stack trace for the current thread
- Implement custom stack walking to support fetching a backtrace for all threads (including the crashed thread)
The first solution is unreliable for a number of reasons, but the failure mode I'll be addressing here is a stack overflow. In the case of a stack overflow, a crash reporter that makes use of backtrace(3) or similar APIs will be entirely unable to report the crash. Here's a code example that will accidentally trigger an overflow:
/* A small typo can trigger infinite recursion ... */
NSArray *resultMessages = [NSMutableArray arrayWithObject: @"Error message!"];
NSMutableArray *results = [[NSMutableArray alloc] init];
for (NSObject *result in resultMessages)
[results addObject: results]; // Whoops!
NSLog(@"Results: %@", results);
If the crash reporter makes use of backtrace(3), this crash will not be reported. The reason is straight-forward: These backtrace APIs must execute on on the crashed thread's stack, but that stack just overflowed. There is is no stack space within which the crash reporter's signal handler can be run.
However, if the crash reporter uses sigaltstack() to correctly execute on a different stack, the backtrace will be empty — the signal handler is running on a new stack!
In PLCrashReporter, this was solved by implementing custom stack walking for the supported platforms. This requires more complexity, but in addition to supporting the generation of reports in the case of stack overflow, also allows the crash reporter to provide stack traces for all running threads.
Conclusion
Implementing a reliable crash reporter is difficult, and these are only a brief overview of the potential pitfalls and complexities involved. I think Mike Ash best described the complexity of signal handlers in Friday Q&A:
There is very little that you can do safely. There is so little that I'm not even going to discuss how to get anything done, because it's so impractical to do so, and instead will simply tell you to avoid using signal handlers unless you really know what you're doing and you enjoy pain.
While I can't claim that PLCrashReporter is perfect, great effort (and pain) have been expended in ensuring its reliability and correctness. If you're considering implementing your own ad-hoc reporter, I'd highly recommend reviewing the design decisions made in both Google Breakpad and PLCrashReporter, both of which are liberally licensed and may be included in any commercial and/or closed-source product.
As a developer considering the use of a crash reporter in your application, I hope this overview will provide a little more insight into their function (and design complexities), as well as providing you with some tools to evaluate the efficacy of the available solutions -- complex failure cases are often the time when you need accurate, reliable crash reporting the most.
Implementing imp_implementationWithBlock()
14 Apr 2011, 06:46 PDTIn iOS 4.3, Apple introduced a new API to support the use of blocks as Objective-C method implementations. The API provides similar functionality as Mike Ash's MABlockClosure, which uses libffi (or libffi-ios) to implement support for generating arbitrary function pointers that dispatch to a block.
However, Apple's new API differs from MABlockClosure in a few important ways:
- Only Obj-C IMP-compatible function pointers may be generated.
- No knowledge of the block's type signature is required (with some caveats we'll discuss below).
- The trampoline is lightweight (just a few instructions), this is faster than libffi-based dispatch as used by MABlockClosure.
Today, I'll be discussing how block-based message dispatch is implemented by Apple, and how you can implement your own similar, custom trampolines on iOS and Mac OS X. Additionally, I've posted PLBlockIMP on github. This project provides:
- An open-source implementation of imp_implementationWithBlock() for Mac OS X 10.6+ and iOS 4.0+ (ARM, i386, and x86-64).
- Generalized code to support automated generation of arbitrary trampoline pages on Darwin, based on the trampoline allocator I wrote for libffi-ios.
In addition to this article, Bill Bumgarner has written an excellent introduction to imp_implementationWithBlock, and if you need a refresher in objective message dispatch, Mike Ash has a more in-depth explanation here.
This work has been funded by my employer, Plausible Labs. We specialize in Mac OS X, iOS, and Android development and we're available for hire.
Creating Trampolines without Writable Code
The implementation of imp_implementationWithBlock() relies on trampolines to convert between Objective-C method calls and block dispatch. Trampolines are small pieces of code that, when called, perform some intermediary operations and then jump to the actual target destination. When you call imp_implementationWithBlock(), a function pointer to a trampoline is returned; it's this trampoline's responsibility to modify the function arguments and then jump to the actual code corresponding to the block's implementation.
Trampolines often require more information than can be derived from their function parameters -- such is the case with our IMP trampolines, which must have a pointer to the target block that they should call. Historically, this type of trampoline has generally been implemented through the use of writable code pages; the instructions are written to a PROT_EXEC|PROT_WRITE page at runtime, with any additional context information included directly in the generated code.
Unfortunately, iOS has instituted a restriction on the use of writable, executable pages (although there are signs that this may eventually be lifted), necessitating the use of an alternative mechanism for implementing trampoline-specific context data. While iOS does not allow the use of writable code, we can leverage a combination of vm_remap() and PC-relative addressing to implement configurable trampolines without writable code.
On Darwin, vm_remap() provides support for mapping an existing code page at new address, while retaining the existing page protections; using vm_remap(), we can create multiple copies of existing, executable code, placed at arbitrary addresses. If we generate a template page filled with trampolines at build time, we can create arbitrary duplicates of that page at runtime. This allows us to allocate an arbitrary number of trampolines using that template without requiring writable code:

Figure 1: vm_remap()
However, executable trampoline allocation only solves half the problem -- we still need a way to configure each trampoline.
The solution is PC-relative addressing. The processor's program counter register indicates the address of the currently executing instruction; PC-relative addressing uses the program counter to address memory relative to the currently executing instruction. When we remap our trampolines and then jump to them, each trampoline is executing at a unique address. If we then map a writable data page next to our trampoline page, we can use PC-relative addressing to load per-trampoline data from adjacent writable data page:
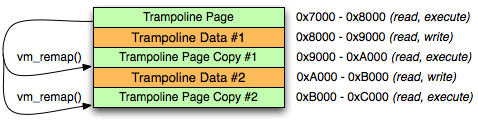
Figure 2: vm_remap() with writable data pages
Once a full page of trampolines are allocated, we simply need to provide the individual trampolines on request, and allocate additional pages if the pool of trampolines is exhausted. A full implementation of a trampoline allocator is available in PLBlockIMP; refer to pl_trampoline_alloc(), pl_trampoline_data_ptr(), and pl_trampoline_free().
To save space within our trampoline page, each individual trampoline saves the PC register, and then jumps to a common implementation at the start of the trampoline page. The ARM implementation of the individual trampoline stub is two instructions:
mov r12, pc b _block_tramp_dispatch;
IMP->Block Dispatch (self, _cmd, and Block)
As noted in Bill Bumgarner's article on imp_implementationWithBlock, every Objective-C method has two implicit, pointer-sized arguments at the head of the method's argument list: self, and _cmd. Likewise, block implementations also have an implicit first argument; the block literal, which maintains the block's reference count, bock descriptor, references to captured variables, and other block data.
When called, a trampoline returned by imp_implementationWithBlock() is responsible for re-ordering its arguments to match those required by the block's implementation: the 'self' argument must be moved to second argument slot (overwriting _cmd), and the block literal moved to the (now vacated) first argument slot.
However, there is one wrinkle that Bill didn't touch on: structure return values. On the current architectures supported by Darwin, functions that return structures by value may have an additional pointer at the start of their argument list. This pointer is used to provide the address on the caller's stack at which the structure return value should be written.
In the case where structure return (stret) calling conventions are used, the structure return pointer in the first argument slot must remain unmodified, the block literal argument must be in the second argument slot, and the self pointer in the third. This requires that imp_implementationWithBlock() provide two different trampoline implementations to support both calling conventions, and that the requisite trampoline type for a block be determined when imp_implementationWithBlock is called.
There is no way to determine from a raw function pointer whether a function requires stret calling conventions -- to work around this, Apple's compilers set an additional flag, BLOCK_USE_STRET, when emitting a block that requires the stret calling conventions. This flag may be used to easily determine the necessarily trampoline type for a block.
As described in the previous section, the individual trampolines save their PC address and then immediately jump to a shared implementation at the start of the trampoline page. That shared implementation re-orders the existing arguments, loads the block literal from its PC-relative configuration data, and then jumps to the block's implementation -- on ARM, our non-stret shared implementation looks like this:
_block_tramp_dispatch:
# trampoline address+8 is in r12 -- calculate our config page address
sub r12, #0x8
sub r12, #0x1000
# Set the 'self' argument as the second argument
mov r1, r0
# Load the block pointer as the first argument
ldr r0, [r12]
# Jump to the block pointer
ldr pc, [r0, #0xc]
Conclusion
While I still have my fingers crossed for PROT_EXEC|PROT_WRITE pages on iOS, vm_remap()-based trampolines can serve as a viable replacement for some tasks. If you have further questions, or ideas for other neat projects worth tackling, feel free to drop me an e-mail.
Work with Plausible Labs
18 Feb 2010, 10:26 PSTWhen I started Plausible Labs in 2008, we were working out of our homes, paying our rent out of savings while we figured out how to bootstrap worker-owned software cooperative without external funding.
A year or so later, I'm part of a three member team. We are all still working out of a home, but now it's a loft in the Mission with proper office space, Ikea desks, and even a few Aeron chairs. We've got the issue of self-sufficiency figured out, and now we're looking to the future -- how we'd like to grow our organization, what sort of software projects we'd like to tackle (both in-house and on contract), and how the co-operative experiment will scale past a few members.
We're ready to take on more (and larger) projects, and we’d like to find the right engineer for a contract-to-hire role to help us out. We’re particularly keen in finding someone genuinely interested in joining the co-operative, and open to working with us on either a part-time or full-time basis.
If you'd be interested in working with us, you can find the job posting here.
OpenJDK 7 on Leopard PPC
16 Dec 2009, 17:29 PSTIntroduction
Thanks to the work of Gary Benson on implementing and merging the Zero-Assembler Project, and Greg Lewis' work bringing it to OpenJDK BSD Port, it's now possible to bootstrap OpenJDK 7 on Mac OS X 10.5/PPC.
Gary Benson's Zero Assembler provides a portable implementation of the JVM intepreter that -- unlike the existing JVM implementations -- relies on very little assembler to provide an acceptably performing but highly portable VM, opening the door to supporting Mac OS X PPC with very little additional work.
I've committed the few small fixes to get OpenJDK running on Mac OS X 10.5/PPC, and have bootstrapped an initial OpenJDK 7 binary using Havard Eidnes's bootstrap scripts. Bootstrapping the initial VM running is sufficiently involved that I would recommend using my binaries (openjdk7-macppc-2009-12-16-b4.tar.bz2).
Source Access
OpenJDK uses Mercurial with the Forest extension. Before checking out the BSD sources, you will need to install and configure Mercurial. See the OpenJDK Developer's Guide for more information.
To check out the BSD-Port forest:
hg fclone http://hg.openjdk.java.net/bsd-port/bsd-port
Building on Leopard/PPC
Building OpenJDK requires Java 6 or OpenJDK 7 -- on PPC, you will need to download or build an OpenJDK 7 bootstrap VM (openjdk7-macppc-2009-12-16-b4.tar.bz2).
To build the JDK in build/bsd-ppc/j2sdk-image:
make \ CC=gcc-4.0 \ CXX=g++-4.0 \ ALT_BOOTDIR=/usr/local/openjdk7-macppc-2009-12-16-b4 ANT_HOME=/usr/share/ant \ ALT_FREETYPE_HEADERS_PATH=/usr/X11/include \ ALT_FREETYPE_LIB_PATH=/usr/X11/lib \ ALT_CUPS_HEADERS_PATH=/usr/include \ ALT_CACERTS_FILE=/System/Library/Frameworks/JavaVM.framework/Home/lib/security/cacerts \ LIBFFI_CFLAGS="-I/usr/include/ffi" \ NO_DOCS=true \ ZERO_BUILD=true \ ZERO_ENDIANNESS=big \ ZERO_LIBARCH=ppc \ ZERO_ARCHDEF=PPC \ ZERO_ARCHFLAG=-m32
Be sure to set ALT_BOOTDIR to the path of your installed openjdk7-macppc-2009-12-16-b4 bootstrap JDK.
Once built, you should now have a JDK in build/bsd-ppc/j2sdk-image:
landonf@onefish:~/openjdk-ppc/bsd-port> ./build/bsd-ppc/j2sdk-image/bin/java -version openjdk version "1.7.0-internal" OpenJDK Runtime Environment (build 1.7.0-internal-landonf_2009_12_16_12_54-b00) OpenJDK Zero VM (build 17.0-b05, interpreted mode)
For more information or assistance, please refer to the OpenJDK BSD-Port wiki and mailing list. My testing has been very limited -- if you run into issues, please report them on the development mailing list.